


 400 998 0226
400 998 0226表计算函数
- 版本 :2022.1 及更高版本
适用于: Tableau Desktop, Tableau Online, Tableau Public, Tableau Server
本文介绍表计算函数及其在 Tableau 中的用法。它还演示如何使用计算编辑器创建表计算。
为何使用表计算函数
表计算函数允许您对表中的值执行计算。
例如,您可以计算某个年度和若干年度个别销售额占总额的百分比。
Tableau 中可用的表计算函数
FIRST( )
返回从当前行到分区中第一行的行数。例如,下面的视图显示每季度销售额。在 Date 分区中计算 FIRST() 时,第一行与第二行之间的偏移为 -1。

示例
当前行索引为 3 时,FIRST() = -2。
INDEX( )
返回分区中当前行的索引,不包含与值有关的任何排序。第一个行索引从 1 开始。例如,下表显示每季度销售额。当在 Date 分区中计算 INDEX() 时,各行的索引分别为 1、2、3、4 等。

示例
对于分区中的第三行,INDEX() = 3。
LAST( )
返回从当前行到分区中最后一行的行数。例如,下表显示每季度销售额。在 Date 分区中计算 LAST() 时,最后一行与第二行之间的偏移为 5。

示例
当前行索引为 3(共 7 行)时,LAST() = 4。
LOOKUP(expression, [offset])
返回目标行(指定为与当前行的相对偏移)中表达式的值。使用 FIRST() + n 和 LAST() - n 作为相对于分区中第一行/最后一行的目标偏移量定义的一部分。如果省略了 offset,则可以在字段菜单上设置要比较的行。如果无法确定目标行,则此函数返回 NULL。
下面的视图显示每季度销售额。当在 Date 分区中计算 LOOKUP (SUM(Sales), 2) 时,每行都会显示接下来 2 个季度的销售额值。

示例
LOOKUP(SUM([Profit]), FIRST()+2) 计算分区第三行中的 SUM(Profit)。
MODEL_PERCENTILE(target_expression, predictor_expression(s))
返回期望值小于或等于观察标记的概率(介于 0 和 1 之间),由目标表达式和其他预测因子定义。这是后验预测分布函数,也称为累积分布函数 (CDF)。
此函数是 MODEL_QUANTILEL 的逆函数。有关预测建模函数的信息,请参见预测建模函数在 Tableau 中的工作方式。
示例
以下公式返回销售额总和标记的分位数,根据订单计数进行调整。
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
以指定的分位数返回由目标表达式和其他预测因子定义的可能范围内的目标数值。这是后验预测分位数。
此函数是 MODEL_PERCENTILE 的逆函数。有关预测建模函数的信息,请参见预测建模函数在 Tableau 中的工作方式。
示例
以下公式返回中位数 (0.5) 预测销售额总和,根据订单数进行调整。
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
返回此计算在上一行中的值。如果当前行是分区的第一行,则返回给定表达式。
示例
SUM([Profit]) * PREVIOUS_VALUE(1) 计算 SUM(Profit) 的运行产品。
RANK(expression, ['asc' | 'desc'])
返回分区中当前行的标准竞争排名。为相同的值分配相同的排名。使用可选的 'asc' | 'desc' 参数指定升序或降序顺序。默认为降序。
利用此函数,将对值集 (6, 9, 9, 14) 进行排名 (4, 2, 2, 1)。
在排名函数中,会忽略 Null。它们不进行编号,且不计入百分位排名计算的总记录数中。
有关不同排名选项的信息,请参见排名计算。
示例
下图显示对一组值执行各种排名函数(RANK、RANK_DENSE、RANK_MODIFIED、RANK_PERCENTILE 和 RANK_UNIQUE)的效果。数据集包含 14 名学生(StudentA 到 StudentN)的相关信息;“Age”列显示每个学生的当前年龄(所有学生都介于 17 岁和 20 岁之间)。其余的列会显示每个排名函数对年龄值集的影响,并始终假定函数的默认顺序(升序或降序)。
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
返回分区中当前行的密集排名。为相同的值分配相同的排名,但不会向数字序列中插入间距。使用可选的 'asc' | 'desc' 参数指定升序或降序顺序。默认为降序。
利用此函数,将对值集 (6, 9, 9, 14) 进行排名 (3, 2, 2, 1)。
在排名函数中,会忽略 Null。它们不进行编号,且不计入百分位排名计算的总记录数中。
有关不同排名选项的信息,请参见排名计算。
RANK_MODIFIED(expression, ['asc' | 'desc'])
返回分区中当前行的调整后竞争排名。为相同的值分配相同的排名。使用可选的 'asc' | 'desc' 参数指定升序或降序顺序。默认为降序。
利用此函数,将对值集 (6, 9, 9, 14) 进行排名 (4, 3, 3, 1)。
在排名函数中,会忽略 Null。它们不进行编号,且不计入百分位排名计算的总记录数中。
有关不同排名选项的信息,请参见排名计算。
RANK_PERCENTILE(expression, ['asc' | 'desc'])
返回分区中当前行的百分位排名。使用可选的 'asc' | 'desc' 参数指定升序或降序顺序。默认为升序。
利用此函数,将对值集 (6, 9, 9, 14) 进行排名 (0, 0.67, 0.67, 1.00)。
在排名函数中,会忽略 Null。它们不进行编号,且不计入百分位排名计算的总记录数中。
有关不同排名选项的信息,请参见排名计算。
RANK_UNIQUE(expression, ['asc' | 'desc'])
返回分区中当前行的唯一排名。为相同的值分配相同的排名。使用可选的 'asc' | 'desc' 参数指定升序或降序顺序。默认为降序。
利用此函数,将对值集 (6, 9, 9, 14) 进行排名 (4, 2, 3, 1)。
在排名函数中,会忽略 Null。它们不进行编号,且不计入百分位排名计算的总记录数中。
有关不同排名选项的信息,请参见排名计算。
RUNNING_AVG(expression)
返回给定表达式从分区中第一行到当前行的运行平均值。
下面的视图显示每季度销售额。当在 Date 分区中计算 RUNNING_AVG(SUM([Sales]) 时,结果为每个季度的销售额值的运行平均值。

示例
RUNNING_AVG(SUM([Profit])) 计算 SUM(Profit) 的运行平均值。
RUNNING_COUNT(expression)
返回给定表达式从分区中第一行到当前行的运行计数。
示例
RUNNING_COUNT(SUM([Profit])) 计算 SUM(Profit) 的运行计数。
RUNNING_MAX(expression)
返回给定表达式从分区中第一行到当前行的运行最大值。

示例
RUNNING_MAX(SUM([Profit])) 计算 SUM(Profit) 的运行最大值。
RUNNING_MIN(expression)
返回给定表达式从分区中第一行到当前行的运行最小值。

示例
RUNNING_MIN(SUM([Profit])) 计算 SUM(Profit) 的运行最小值。
RUNNING_SUM(expression)
返回给定表达式从分区中第一行到当前行的运行总计。

示例
RUNNING_SUM(SUM([Profit])) 计算 SUM(Profit) 的运行总计
SIZE()
返回分区中的行数。例如,下面的视图显示每季度销售额。在 Date 分区中有七行,因此 Date 分区的 Size() 为 7。

示例
当前分区包含五行时 SIZE() = 5。
SCRIPT_BOOL
返回指定表达式的布尔结果。表达式直接传递给正在运行的分析扩展程序服务实例。
在 R 表达式中,使用 .argn(带前导句点)引用参数(.arg1、.arg2 等)。
在 Python 表达式中,使用 _argn(带前导下划线)。
示例
在此 R 示例中,.arg1 等于 SUM([Profit]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
对于华盛顿州中的商店 ID,下一示例返回 True,否则返回 False。此示例可以是标题为 IsStoreInWA 的计算字段的定义。
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Python 的命令将采用以下形式:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
返回指定表达式的整数结果。表达式直接传递给正在运行的分析扩展程序服务实例。
在 R 表达式中,使用 .argn(带前导句点)引用参数(.arg1、.arg2 等)
在 Python 表达式中,使用 _argn(带前导下划线)。
示例
在此 R 示例中,.arg1 等于 SUM([Profit]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
在下一示例中,使用 k-means clustering 创建三个群集:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Python 的命令将采用以下形式:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
返回指定表达式的实数结果。表达式直接传递给正在运行的分析扩展程序服务实例。在
在 R 表达式中,使用 .argn(带前导句点)引用参数(.arg1、.arg2 等)
在 Python 表达式中,使用 _argn(带前导下划线)。
示例
在此 R 示例中,.arg1 等于 SUM([Profit]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
下一示例将温度值从摄氏值转换为华氏值。
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Python 的命令将采用以下形式:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
返回指定表达式的字符串结果。表达式直接传递给正在运行的分析扩展程序服务实例。
在 R 表达式中,使用 .argn(带前导句点)引用参数(.arg1、.arg2 等)
在 Python 表达式中,使用 _argn(带前导下划线)。
示例
在此 R 示例中,.arg1 等于 SUM([Profit]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
下一示例将从更复杂的字符串(采用原始格式 13XSL_CA, A13_WA)中提取州名缩写:
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Python 的命令将采用以下形式:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
TOTAL(expression)
返回表计算分区内表达式的总计。
示例
假定您从此视图开始:

您可以打开计算编辑器并创建名为“总额”的新字段。

然后可以将“总额”拖到“文本”上以替换 SUM(Sales)。您的视图会发生更改,使其总计值基于默认的“计算依据”值:

这会产生问题,默认的“计算依据”值是什么?如果在“数据”窗格中右键单击(在 Mac 上按住 Control 单击)“总额”,并选择“编辑”,则会提供一点额外的信息:

默认的“计算依据”值是“表(横穿)”。结果是,“总额”会汇总每个表行的值。因此,您看到的每一行的值是表原始版本中值的总和。
原始表内 2011/Q1 行中的值为 $8601、$6579、$44262 和 $15006。在“总额”替换 SUM(Sales) 之后,表中的值都为 $74,448,这是四个原始值的总和。
请注意,将“总额”拖到“文本”上之后“总额”旁边会出现小三角:

这表明该字段正在使用表计算。您可以右键单击字段并选择“编辑表计算”,以将您的函数重定向到不同的“计算依据”值。例如,可以将其设置为“表(向下)”。在此情况下,您的表将如下所示:

WINDOW_AVG(expression, [start, end])
返回窗口中表达式的平均值。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
例如,下面的视图显示每季度销售额。Date 分区中的窗口平均值返回所有日期间的平均销售额。
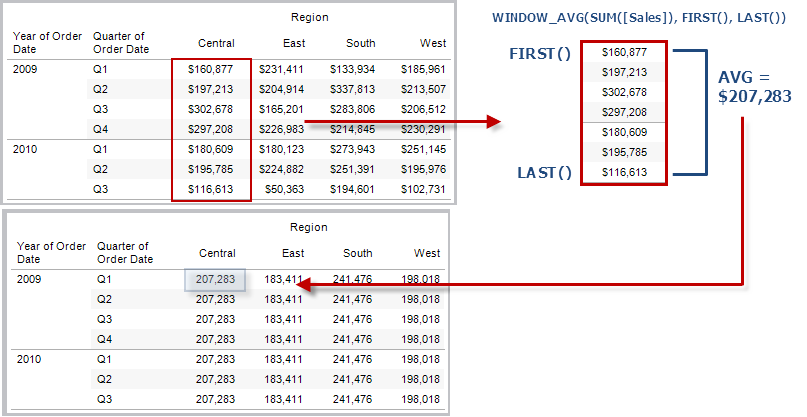
示例
WINDOW_AVG(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 平均值。
WINDOW_CORR(expression1, expression2, [start, end])
返回窗口内两个表达式的皮尔森相关系数。窗口定义为与当前行的偏移。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了 start 和 end,则使用整个分区。
皮尔森相关系数衡量两个变量之间的线性关系。结果范围为 -1 至 +1(包括 -1 和 +1),其中 1 表示精确的正向线性关系,比如一个变量中的正向更改即表示另一个变量中对应量级的正向更改,0 表示方差之间没有线性关系,而 −1 表示精确的反向关系。
有一个等效的聚合函数:CORR。请参阅 Tableau 函数(按字母顺序)。
示例
以下公式返回 SUM(Profit) 和 SUM(Sales) 从前五行到当前行的皮尔森相关系数。
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
返回窗口中表达式的计数。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 计数
WINDOW_COVAR(expression1, expression2, [start, end])
返回窗口内两个表达式的样本协方差。窗口定义为与当前行的偏移。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了 start 和 end 参数,则窗口为整个分区。
样本协方差使用非空数据点的数量 n - 1 来规范化协方差计算,而不是使用总体协方差(及 WINDOW_COVARP 函数)所使用的 n。当数据是用于估算较大总体的协方差的随机样本时,则样本协方差是合适的选择。
有一个等效的聚合函数:COVAR。请参阅 Tableau 函数(按字母顺序)。
示例
以下公式返回 SUM(Profit) 和 SUM(Sales) 从前两行到当前行的样本协方差。
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
返回窗口内两个表达式的总体协方差。窗口定义为与当前行的偏移。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了 start 和 end,则使用整个分区。
总体协方差等于样本协方差除以 (n-1)/n,其中 n 是非空数据点的总数。如果存在可用于所有相关项的数据,则总体协方差是合适的选择,与之相反,在只有随机项子集的情况下,样本协方差(及 WINDOW_COVAR 函数)较为适合。
有一个等效的聚合函数:COVARP。Tableau 函数(按字母顺序)。
示例
以下公式返回 SUM(Profit) 和 SUM(Sales) 从前两行到当前行的总体协方差。
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
返回窗口中表达式的中值。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
例如,下面的视图显示每季度利润。Date 分区中的窗口中值返回所有日期的中值利润。

示例
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 中值。
WINDOW_MAX(expression, [start, end])
返回窗口中表达式的最大值。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
例如,下面的视图显示每季度销售额。Date 分区中的窗口最大值返回所有日期间的最大销售额。

示例
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 最大值。
WINDOW_MIN(expression, [start, end])
返回窗口中表达式的最小值。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
例如,下面的视图显示每季度销售额。Date 分区中的窗口最小值返回所有日期间的最小销售额。

示例
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 最小值。
WINDOW_PERCENTILE(expression, number, [start, end])
返回与窗口中指定百分位相对应的值。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) 返回 SUM(Profit) 的前面两行到当前行的第 75 个百分位。
WINDOW_STDEV(expression, [start, end])
返回窗口中表达式的样本标准差。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 标准差。
WINDOW_STDEVP(expression, [start, end])
返回窗口中表达式的有偏差标准差。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 标准差。
WINDOW_SUM(expression, [start, end])
返回窗口中表达式的总计。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
例如,下面的视图显示每季度销售额。Date 分区中计算的窗口总计返回所有季度的销售额总计。

示例
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 总和。
WINDOW_VAR(expression, [start, end])
返回窗口中表达式的样本方差。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 方差。
WINDOW_VARP(expression, [start, end])
返回窗口中表达式的有偏差方差。窗口用与当前行的偏移定义。使用 FIRST()+n 和 LAST()-n 表示与分区中第一行或最后一行的偏移。如果省略了开头和结尾,则使用整个分区。
示例
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) 计算从第二行到当前行的 SUM(Profit) 方差。
使用计算编辑器创建表计算
请按照以下步骤学习如何使用计算编辑器创建表计算。
注意:可以通过多种方式在 Tableau 中创建表计算。此示例仅演示其中一种方式。有关详细信息,请参见使用表计算转换值。
步骤 1:创建可视化项
在 Tableau Desktop 中,连接到 Tableau 附带的“Sample - Superstore”已保存数据源。
导航到工作表。
从“数据”窗格中的“维度”下,将“Order Date”(订单日期)拖到“列”功能区。
从“数据”窗格中的“维度”下,将“Sub-Category”(子类)拖到“行”功能区。
从“数据”窗格中的“度量”下,将“Sales”(销售额)拖到“标记”卡上的“文本”。
您的可视化项将更新为文本表。

步骤 2:创建表计算
选择“分析”>“创建计算字段”。
在打开的计算编辑器中,执行以下操作:
将计算字段命名为“Running Sum of Profit”(利润运行总和)。
输入以下公式:
RUNNING_SUM(SUM([Profit]))此公式计算利润销售额的运行总和。它跨整个表进行计算。
完成后,单击“确定”。
新的表计算字段将出现在“数据”窗格中的“度量”下。就像其他字段一样,您可以在一个或多个可视化项中使用该字段。
步骤 3:在可视化项中使用表计算
从“数据”窗格中的“度量”下,将“Running Sum of Profit”(利润运行总和)拖到“标记”卡上的“颜色”。
在“标记”卡上,单击“标记类型”下拉列表,并选择“方块”。
可视化项将更新为突出显示表:

步骤 4:编辑表计算
在“标记”卡上,右键单击“Running Sum of Profit”(利润运行总和),并选择“编辑表计算”。
在打开的“表计算”对话框中的“计算依据”下,选择“表(向下)”。
可视化项将更新为如下:
