


 400 998 0226
400 998 0226Power BI Desktop 中的数据类型
- 版本 :2023.1(当前版本)
Power BI Desktop 中的数据类型
本文介绍 Power BI Desktop 和数据分析表达式 (DAX) 中支持的数据类型。
当你将数据加载到 Power BI Desktop 中时,它将尝试将源列的数据类型转换为能更好地支持更高效的存储、计算和数据可视化的数据类型。 例如,如果从 Excel 导入的值的列没有小数值,Power BI Desktop 会将整个数据列转换为整数数据类型,这能更好地存储整数。
这一概念很重要,因为某些 DAX 函数具有特殊的数据类型要求。 虽然在许多情况下 DAX 会为你隐式转换数据类型,但在某些情况下,它不会进行转换。 例如,如果 DAX 函数需要日期数据类型,而你的列的数据类型为文本,DAX 函数将不能正常工作。 因此,获取适用于列的正确数据类型是重要并且有用的。 隐式转换将会在本文的后一部分进行介绍。
确定并指定列的数据类型
在 Power BI Desktop 中,你可以在 Power Query 编辑器(或数据视图和报表视图中)确定并指定列的数据类型:
Power Query 编辑器中的数据类型
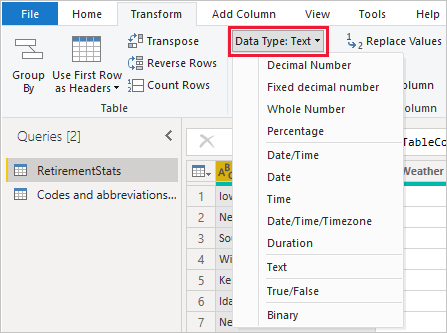
数据视图或报表视图中的数据类型
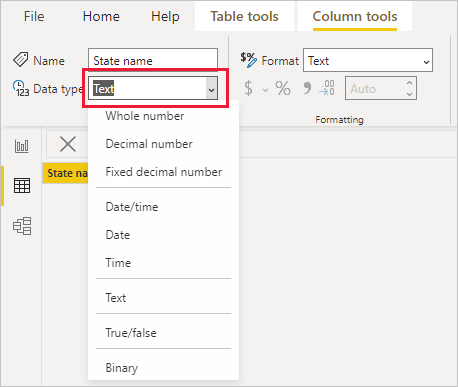
Power Query 编辑器中的“数据类型”下拉列表中有两种数据类型在当前数据或报表视图中不存在,分别是“日期/时间/时区”和“持续时间” 。 当将使用这些数据类型的列加载到模型中,并在数据或报表视图中进行查看时,使用日期/时间/时区数据类型的列将会被转换为日期/时间,而使用持续时间数据类型的列将会被转换为十进制数字。
当前在 Power Query 编辑器外部不支持“二进制”数据类型。 在 Power Query 编辑器中,如果先将二进制文件转换为其他数据类型,然后再将它加载到 Power BI 模型,则可以在加载这些文件时使用该类型。 由于旧原因,它存在于数据视图和报表视图菜单中,但如果尝试将二进制列加载到 Power BI 模型,则可能会遇到错误。
数字类型
Power BI Desktop 支持三种数字类型:
十进制数 – 表示 64 位(八字节)浮点数。 它是最常见的数字类型,与你通常想象的数字相对应。 虽然十进制数类型被设计为处理带小数值的数字,但还可以处理整数。 十进制数类型可以处理从 -1.79E +308 到 -2.23E -308 的负值、0,以及从 2.23E -308 到 1.79E + 308 的正值。 例如,34、34.01 和 34.000367063 等数字都是有效的十进制数。 可以用十进制数类型表示的最大精度为 15 位数。 小数分隔符可出现在数字的任意位置。 十进制数类型与 Excel 存储其数字的方式相对应。 十进制数数据类型在表格对象模型 (TOM) 中指定为 DataType.Double 枚举类型 1。
定点十进制数 – 小数分隔符的位置是固定的。 小数分隔符右侧始终有四位数,并可以表示有意义的 19 位数。 它可以表示的最大值为 922,337,203,685,477.5807(正或负)。 定点十进制数类型在舍入可能会引发错误的情况下非常有用。 在处理许多带小数值的数字时,有时它们会累积并强制性地使数据稍有偏离。 由于小数分隔符右侧四位数其后的数字会被截断,定点十进制数可以帮助你避免这些类型的错误。 如果你熟悉 SQL Server,此数据类型可对应于 SQL Server 的十进制 (19,4),或 Analysis Services 中的货币数据类型和 Excel 中的 Power Pivot。 定点十进制数数据类型在 TOM 中指定为 DataType.Decimal 枚举类型 1。
整数 – 表示 64 位(八字节)整数值。 由于它是一个整数,其小数位数右侧没有数字。 它支持 19 位数;从 -9,223,372,036,854,775,807 (-2^63+1) 到 9,223,372,036,854,775,806 (2^63-2) 的正数或负数。 它可以表示各种数值数据类型可能的最大精度。 与定点十进制数类型相同,在需要控制舍入的情况下,整数类型非常有用。 整数数据类型在 TOM 中指定为 DataType.Int64 枚举类型 1。
备注
Power BI Desktop 数据模型支持 64 位整数值,但由于存在 JavaScript 限制,因此视觉对象可安全表达的最大数字是 9,007,199,254,740,991 (2^53-1)。 如果在数据模型中使用大于以上值的数字,可在将该数字添加到视觉对象前,通过计算减小其大小。
1 - DataType 枚举在表格列 DataType 属性中指定。 若要详细了解如何以编程方式修改 Power BI 中的对象,请参阅使用表格对象模型对 Power BI 数据集进行编程。
确保数字类型计算的准确性
根据关于浮点数的 IEEE 754 标准,“小数”数据类型的列值存储为“近似”数据类型。 近似数据类型在其精度方面存在固有限制,因为它们可能被存储为非常接近或舍入的近似值,而不是存储数字的确切值。 这意味着,如果无法在浮点值中可靠地量化浮点位数,则可能会发生精度损失或不精确。 在一些报告的场景中,不精确的可能性表现为意外或不准确的计算结果。
在小数数据类型的值之间执行等式相关比较(=、<>、>= 和 <=)的计算可能会返回意外结果。 这在 DAX 表达式中使用 RANKX 函数时最为明显,该表达式计算了两次结果,导致数字略有不同。 报表用户不会注意到这两个数字之间的差异,但排名结果会显而易见地不准确。 为避免意外结果,你可以将列数据类型从“小数”更改为“定点小数”或“整数”,或者使用舍入强制舍入。 “固定小数”数据类型具有更高的精度,因为小数分隔符的右侧总是有四位数字。
虽然很少见,但对“小数”数据类型的列值进行求和的计算可能会返回意外结果。 这很可能出现在同时具有大量正数和大量负数的列中。 求和结果受列中各行的值分布的影响。 如果返回查询结果所需的计算在对大多数负数求和之前对大多数正数求和,则开头的部分和可能会丢失精度,因为它可能会因较大的正部分和而偏斜。 另一方面,如果查询恰好添加平衡的正负数,则总和将保持更高的精度,从而返回更准确的结果。 为避免出现意外结果,你可以将列数据类型从“小数”更改为“固定小数”或“整数”。
日期/时间类型
Power BI Desktop 支持查询视图中的五种日期/时间数据类型。 在加载到模型的过程中,日期/时间/时区和持续时间都将被转换。 Power BI Desktop 数据模型只支持日期/时间,但它们可以独立地格式化为日期或时间。
日期/时间 – 表示日期和时间值。 实际上,日期/时间值是以十进制数类型进行存储的。 因此你实际上可以在这两种类型之间进行转换。 日期的时间部分存储为 1/300 秒 (3.33 ms) 的整数倍的分数。 支持 1900 年和 9999 年之间的日期。
日期 – 仅表示日期(没有时间部分)。 转换为模型时,日期与表示分数值的带零日期/时间值相同。
时间 – 仅表示时间(没有日期部分)。 转换为模型时,时间值与小数位数左侧没有数字的日期/时间值相同。
日期/时间/时区 – 表示带时区偏移量的 UTC 日期/时间。 将这种数据加载到模型中时,它将被转换为日期/时间类型。 Power BI 模型不会根据用户的位置或区域设置等调整时区。如果在美国将值 09:00 加载到模型中,则无论在何处打开或查看报表,它都将显示为 09:00。
持续时间 – 表示时间的长度。 加载到模型中时,它将被转换为十进制数类型。 与十进制数类型相同,可将其添加到日期/时间字段,或从日期/时间字段中减去,并获取正确的结果。 与十进制数类型相同,你可以在显示度量值的可视化效果中轻松地使用它。
文本类型
文本 - Unicode 字符数据字符串。 可以是字符串、数字或文本格式表示的日期。 其最大字符串长度为 268,435,456 Unicode 字符(256 Mega 字符)或 536,870,912 字节。
Power BI 存储数据的方式可便于它在特定情况下以不同方式显示数据。 本部分介绍了如下常见情形:在使用 Power Query 查询数据之间和加载数据之后,处理文本数据时的情况可能会略有不同。
(不)区分大小写
在 Power BI 中存储和查询数据的引擎不区分大小写 - 这意味着引擎会将不同大小写的字母视为相同的值:a 等于 A。然而 Power Query 是区分大小写的:a 不等于 A。这种区分大小写的差异会导致一种令人费解的情况,即文本数据加载到 Power BI 后大小写发生了改变。 以下简单示例加载了有关订单的数据:OrderNo 列(对于每个订单都是唯一的)和包含收件人姓名的“收件人”列(在下单时手动输入)。 在 Power Query 中,此数据如下所示:
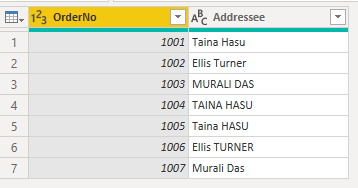
请注意,有多个与收件人同名的订单,尽管输入到系统中的形式略有不同。
当我们在数据加载后转到 Power BI 中的“数据”选项卡时,同一表如下表所示。
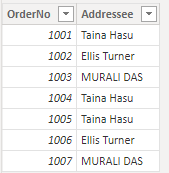
请注意,某些姓名的大小写与最初输入的形式有所不同。 发生这一变化是因为在 Power BI 中存储数据的引擎不区分大小写,会将同一字符的小写和大写版本视为相同。 而 Power Query 则区分大小写,因而造就了这种差异,它显示的数据与源系统中存储的数据完全一致。 但是,第二个屏幕截图中的数据已加载到 Power BI 的引擎中,因此发生了变化。
加载数据时,引擎从顶部开始逐行评估每一行。 对于每个文本列(如收件人),引擎存储一个唯一值的字典,以通过数据压缩实现性能。 在处理收件人列时,引擎遇到的前三个值是唯一的并存储在字典中。 但是,从第四个姓名(顺序 1004)开始,由于引擎不区分大小写,因此该姓名被视为相同:Taina Hasu 与 TAINA HASU 以及 Taina HASU 相同。 因此,引擎不会存储该姓名,而是引用它遇到的第一个姓名。 这也解释了为什么 MURALI DAS 这个姓名是用大写字母写的,因为引擎在从上到下加载数据时第一次评估的就是大写形式的姓名。
下图说明了这一过程:
在上面的示例中,引擎加载第一行数据,创建收件人字典并将 Taina Hasu 添加到其中。 它还在加载的表的“收件人”列中添加对该值的引用。 该引擎对第二、第三行执行相同的操作,因为在忽略大小写的情况下,这两个姓名并不等同于其他姓名。
将第四行的收件人与字典中的姓名进行比较,发现:由于引擎不区分大小写,因此 TAINA HASU 等同于 Taina Hasu。 因此,引擎不会向收件人字典添加新姓名,而是引用现有姓名。 其余行也是如此。
备注
由于在 Power BI 中存储和查询数据的引擎不区分大小写,因此在 DirectQuery 模式下处理区分大小写的源时,必须特别小心。 Power BI 假定源已消除重复行;由于 Power BI 不区分大小写,因此两个只有大小写不同的值将被视为重复行,而源可能不会被视为重复行。 在这种情况下,最终结果未定义,应避免使用。 如果使用的是 DirectQuery 模式并且数据源区分大小写,则必须在源查询或 Power Query 中规范化大小写。
尾随空格
处理包含前导空格或尾随空格的数据时,应使用 Text.Trim 函数删除文本开头或结尾处的空格以避免混淆,因为 Power BI 引擎会自动剪裁任何尾随空格,但不会删除前导空格。 如果不删除前导或尾随空格,可能无法创建关系,因为会检测到重复值,或者视觉对象可能会返回意外结果。 我们在一个简单的示例中加载了客户相关数据:“名称”列(其中包含客户的名称)和“索引”列(对于每个条目都是唯一的)。 请注意,客户名称重复了四次,但每次都包含不同的前导空格和尾随空格组合:
| 行 | 前导空格 | 尾随空格 | 名称(为清楚起见,用引号标示) | 索引 | 文本长度 |
|---|---|---|---|---|---|
| 1 | 否 | 否 | “Dylan Williams” | 1 | 14 |
| 2 | 否 | 是 | “Dylan Williams ” | 10 | 15 |
| 3 | 是 | 否 | “ Dylan Williams” | 20 | 15 |
| 4 | 是 | 是 | “ Dylan Williams ” | 40 | 16 |
随着时间的推移,手动输入数据可能会出现这些变化。 在 Power Query 中,生成的数据如下所示。
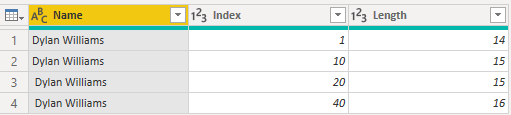
当我们在数据加载后转到 Power BI 中的“数据”选项卡时,同一表如下图所示。
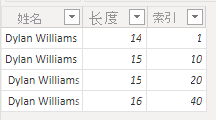
但是,基于此数据的视觉对象仅返回两行。

如上图所示,第一行的“索引”字段总值为“60”,这导致了这样的结论:视觉对象中的第一行表示之前加载的数据的最后两行,而总“索引”值为“11”的第二行表示前两行。 视觉对象和数据表之间的行数间差异是由引擎自动删除(剪裁)任何尾随空格,而不是任何前导空格所致。 所以将第一行、第二行、第三行和第四行视为相同,因此视觉对象会返回这些结果。
使用视觉对象以及处理与关系相关的错误消息时,可能会发生此行为,因为检测到重复值。 例如,根据关系配置,你可能会看到类似于下图的错误。

在其他情况下,可能无法创建多对一或一对一关系,因为检测到重复值。
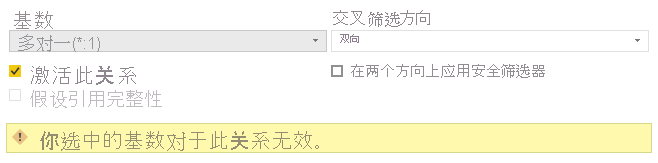
这些错误追溯到前导或尾随空格,可以使用 Text.Trim 函数删除数据转换窗口中的空格来解决。
True/False 类型
True/False – 为 True 或 False 的布尔值。
Power BI 在某些情况下转换和显示数据的方式不同。 本部分介绍转换布尔值的常见情况,以及如何处理在 Power BI 中产生意外结果的转换。
为了获得最佳和最一致的结果,将包含布尔信息 (true/false) 的列加载到 Power BI 中时,请按照以下示例中的描述和说明将列类型设置为 True/False。
本例加载了有关客户是否已订阅时事通讯的数据:TRUE 值表示客户已订阅时事通讯,FALSE 值表示客户尚未订阅。 但是,当我们将报表发布到 Power BI 服务时,我们注意到跟踪新闻通讯订阅状态的列显示为 0 和 -1,而不是预期的 TRUE 或 FALSE 值。 以下涉及查询、发布和刷新数据的步骤集合说明了转换是如何发生的,以及如何解决它们。
此表的简化查询如下图所示。
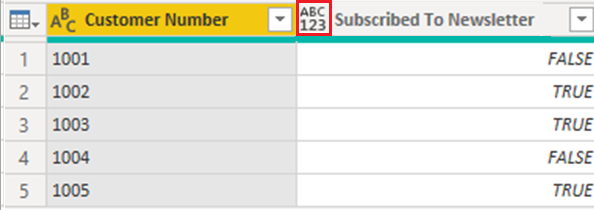
“订阅时事通讯”列的数据类型设置为“任何”,数据类型的这一设置将会导致数据作为文本加载到 Power BI 模型中:
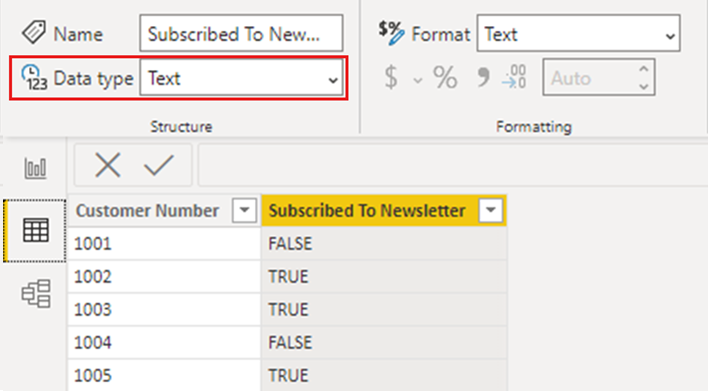
当我们添加显示每个客户详细信息的简单可视化效果时,数据会按预期显示在视觉对象中,无论是在 Power BI Desktop 中,还是在发布到 Power BI 服务时。
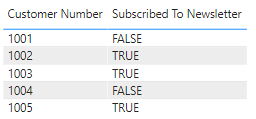
但是,当我们刷新 Power BI 服务中的数据集时,视觉对象中的“订阅时事通讯”列将值显示为 -1 和 0,而不是将其显示为 TRUE 或 FALSE:
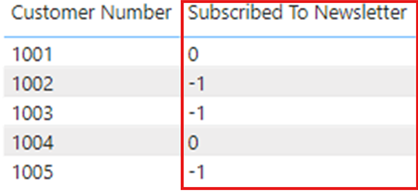
如果我们从 Power BI Desktop 重新发布报表,“订阅时事通讯”列将再次按预期显示 TRUE 或 FALSE,但是一旦 Power BI 服务中发生刷新,这些值将再次更改为显示 -1 和 0。
确保不会发生这种情况的解决方案是在 Power BI Desktop 中将任何布尔列设置为 True/False,然后重新发布报表。
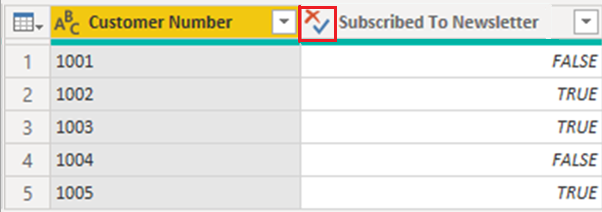
进行更改后,可视化效果将以略有不同的方式显示“订阅时事通讯”列中的值;文本不再是全部是大写字母(如在表中输入的),它们现在是斜体,只有首字母大写,这是更改列数据类型的结果。
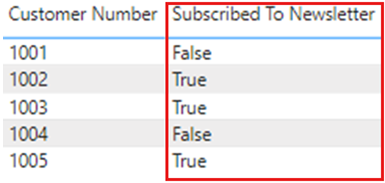
更改数据类型并将其重新发布到 Power BI 服务后,当发生刷新时,值将按预期显示为 True 或 False。
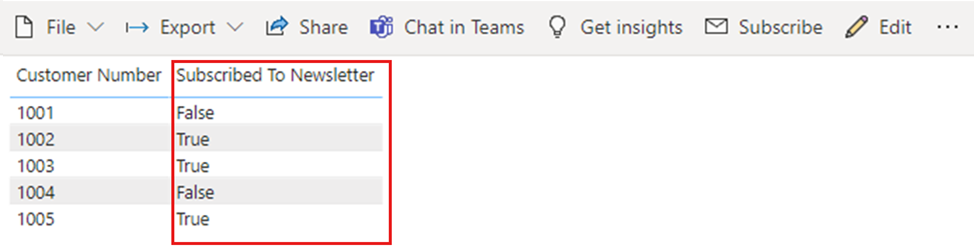
总之,在 Power BI 中处理布尔数据时,请确保在 Power BI Desktop 中将列设置为 True/False 数据类型。
空白/Null 类型
空白 - DAX 中表示和替代 SQL Null 的数据类型。 你可以使用 BLANK 函数创建空白,并使用 ISBLANK 逻辑函数对其进行测试。
二进制数据类型
二进制数据类型可用于表示具有二进制格式的任何其他数据。 在 Power Query 编辑器中,如果先将二进制文件转换为其他数据类型,然后再将它加载到 Power BI 模型,则可以在加载这些文件时使用该类型。 Power BI 数据模型中不支持二进制列。 由于旧原因,它存在于数据视图和报表视图菜单中,但如果尝试将二进制列加载到 Power BI 模型,则可能会遇到错误。
备注
如果二进制列处于查询步骤的输出中,则尝试通过网关刷新数据可能会导致错误。 建议在查询的最后一个步骤中显式删除任何二进制列。
表数据类型
DAX 在许多函数中使用表数据类型,例如聚合和时间智能计算。 某些函数需要引用表;其他函数返回随后可用于输入到其他函数的表。 在某些需要表作为输入的函数中,你可以指定计算结果为表格的表达式;对于一些函数,则需要引用基础表。 有关特定函数的要求的详细信息,请参阅 DAX 函数引用。
DAX 公式中的隐式和显式数据类型转换
关于用作输入和输出的数据类型,每个 DAX 函数都有特定的要求。 例如,某些函数要求对部分参数使用整数,而其他部分使用日期;另外一些函数则要求使用文本或表。
如果将列中与该函数所需数据类型不兼容的数据指定为参数,在很多情况下,DAX 将返回错误信息。 但是,只要可能,DAX 会尝试将数据隐式转换为所需的数据类型。 例如:
你可以以字符串的形式键入日期,DAX 会分析该字符串并尝试将其转换为 Windows 日期和时间格式之一。
你可以添加 TRUE+1 并获得结果 2,因为 TRUE 被隐式转换为数字 1,并执行 1+1 的操作。
如果在两个列中添加值,其中一个值恰好以文本方式表示 ("12"),而另一个值以数字方式表示 (12),DAX 会将字符串隐式转换为数字,然后执行加法并获得数值结果。 下面的表达式将返回 44: = "22" + 22。
如果你尝试连接两个数字,DAX 会将其作为字符串表示并进行连接。 下面的表达式将返回 "1234": = 12 & 34。
隐式数据转换表
执行的转换的类型由运算符确定,它在执行所请求的操作之前会将值转换为所需的值。 这些表列出了运算符,并指示当其与交叉行内的数据类型配对时,对列中每种数据类型执行的转换。
备注
这些表中不包含文本数据类型。 当数字以文本格式表示时,在某些情况下,Power BI 将尝试确定数字类型并将其表示为数字。
加法 (+)
| 运算符 (+) | INTEGER | CURRENCY | REAL | 日期/时间 |
|---|---|---|---|---|
| INTEGER | INTEGER | CURRENCY | REAL | 日期/时间 |
| CURRENCY | CURRENCY | CURRENCY | REAL | 日期/时间 |
| REAL | REAL | REAL | REAL | 日期/时间 |
| 日期/时间 | 日期/时间 | 日期/时间 | 日期/时间 | 日期/时间 |
例如,如果在加法运算中将实数与货币数据结合使用,两个值都会转换为 REAL,并且返回的结果为 REAL。
减法 (-)
下表中,行标题是被减数(左侧),列标题是减数(右侧)。
| 运算符 | INTEGER | CURRENCY | REAL | 日期/时间 |
|---|---|---|---|---|
| INTEGER | INTEGER | CURRENCY | REAL | REAL |
| CURRENCY | CURRENCY | CURRENCY | REAL | REAL |
| REAL | REAL | REAL | REAL | REAL |
| 日期/时间 | 日期/时间 | 日期/时间 | 日期/时间 | 日期/时间 |
例如,如果在减法运算中将日期与其他任何数据类型结合使用,两个值都会转换为日期,返回的值也会是日期。
备注
数据模型还支持一元运算符 - (负号),但此运算符不会更改操作数的数据类型。
乘法 (*)
| 运算符 (*) | INTEGER | CURRENCY | REAL | 日期/时间 |
|---|---|---|---|---|
| INTEGER | INTEGER | CURRENCY | REAL | INTEGER |
| CURRENCY | CURRENCY | REAL | CURRENCY | CURRENCY |
| REAL | REAL | CURRENCY | REAL | REAL |
例如,如果在乘法运算中将整数与实数结合使用,两个数字都会转换成为实数,并且返回的值也是 REAL。
除法 (/)
下表中,行标题是分子(左侧),列标题是分母(右侧)。
| 运算符 (/)(行/列) | INTEGER | CURRENCY | REAL | 日期/时间 |
|---|---|---|---|---|
| INTEGER | REAL | CURRENCY | REAL | REAL |
| CURRENCY | CURRENCY | REAL | CURRENCY | REAL |
| REAL | REAL | REAL | REAL | REAL |
| 日期/时间 | REAL | REAL | REAL | REAL |
例如,如果在除法运算将整数与货币值结合使用,两个值都会转换为实数,并且结果也是实数。
比较运算符
在比较表达式中,布尔值被视为大于字符串值,字符串值被视为大于数字或日期/时间值;数字和时间值被视为同级。 布尔值或字符串值不执行任何隐式转换;BLANK 或空白值会被转换为 0/""/false,具体取决于其他进行比较的值的数据类型。
下面的 DAX 表达式对此行为进行了说明:
=IF(FALSE()>"true","Expression is true", "Expression is false"),返回 "Expression is true"
=IF("12">12,"Expression is true", "Expression is false"),返回 "Expression is true"
=IF("12"=12,"Expression is true", "Expression is false"),返回 "Expression is false"
针对数字或日期/时间类型所执行的隐式转换如下表所述:
| 比较运算符 | INTEGER | CURRENCY | REAL | 日期/时间 |
|---|---|---|---|---|
| INTEGER | INTEGER | CURRENCY | REAL | REAL |
| CURRENCY | CURRENCY | CURRENCY | REAL | REAL |
| REAL | REAL | REAL | REAL | REAL |
| 日期/时间 | REAL | REAL | REAL | 日期/时间 |
空白、空字符串和零值的处理
在 DAX 中,NULL、空值、空单元格或缺失值均以相同的新值类型 BLANK 表示。 你可以使用 BLANK 函数创建空白,并使用 ISBLANK 函数对其进行测试。
空白在运算中的处理方式(例如加法或连接)取决于单个函数。 下表总结了 DAX 和 Microsoft Excel 公式对空白的处理方式的区别。
| 表达式 | DAX | Excel |
|---|---|---|
| BLANK + BLANK | BLANK | 0(零) |
| BLANK + 5 | 5 | 5 |
| BLANK * 5 | BLANK | 0(零) |
| 5/BLANK | 无穷大 | Error |
| 0/BLANK | NaN | Error |
| 空白/空白 | BLANK | Error |
| FALSE OR BLANK | FALSE | FALSE |
| FALSE AND BLANK | FALSE | FALSE |
| TRUE OR BLANK | TRUE | TRUE |
| TRUE AND BLANK | FALSE | TRUE |
| BLANK OR BLANK | BLANK | Error |
| BLANK AND BLANK | BLANK | Error |