


 400 998 0226
400 998 0226在 Power BI Desktop 中应用多对多关系
- 版本 :2023.1(当前版本)
在 Power BI Desktop 中应用多对多关系
使用 Power BI Desktop 中具有多对多基数的关系,可以联接使用多对多基数的表。 此外,还能更轻松、更直观地创建包含两个或多个数据源的数据模型。 具有多对多基数的关系是 Power BI Desktop 中大型“复合模型”功能的一部分。
Power BI Desktop 中的具有多对多基数的关系由三个相关功能组成:
复合模型:“复合模型”允许报表有任意组合的两个或多个数据连接,包括 DirectQuery 连接或导入 。 有关详细信息,请参阅在 Power BI Desktop 中使用复合模型。
具有多对多基数的关系:借助复合模型,可以在表之间建立具有多对多基数的关系。 这种方法删除了对表中唯一值的要求。 它还删除了旧解决办法,如为建立关系而仅引入新表。 本文进一步介绍了此功能。
存储模式:现在可以指定哪些视觉对象需要查询后端数据源。 导入的是不需要查询的视觉对象,即使基于 DirectQuery,也不例外。 此功能有助于提升性能,并减少后端负载。 以前,即使是切片器等简单视觉对象,也会启动发送至后端源的查询。 有关详细信息,请参阅 Power BI Desktop 中的存储模式。
具有多对多基数的关系可解决的问题
在具有多对多基数的关系推出之前,两个表之间的关系是在 Power BI 中定义的。 关系中涉及的至少一个表列必须包含唯一值。 不过,通常没有列包含唯一值。
例如,两个表可能有一个列标记为 CountryRegion。 但在任何一个表中,CountryRegion 的值都不是唯一的。 若要联接此类表,必须创建一个解决方法。 一种解决方法是引入包含所需唯一值的附加表。 借助具有多对多基数的关系,你可以在使用具有多对多基数的关系的情况下直接联接此类表。
使用具有多对多基数的关系
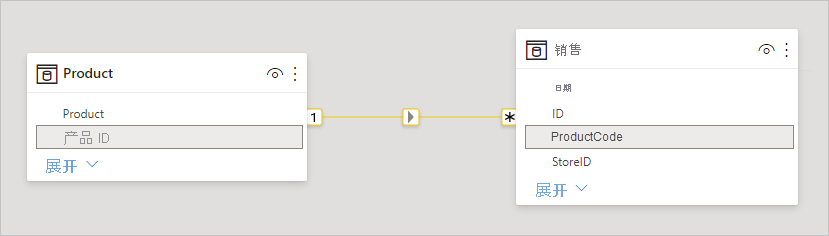
在 Power BI 中定义两个表之间的关系时,必须定义关系基数。 例如,ProductSales 和 Product 之间的关系(使用列 ProductSales[ProductCode] 和 Product[ProductCode])定义为“多对一”。 之所以这样定义关系是因为,每个产品都会有很多销售额,而且 “Product”表中的 (ProductCode) 列是唯一的。 当你将关系基数定义为“多对一”、“一对多”或“1 对 1”后,Power BI 对其进行验证,使选定基数与实际数据匹配 。
例如,请查看此图中的简单模型:
现在,假设“Product” 表只显示两行,如下所示:
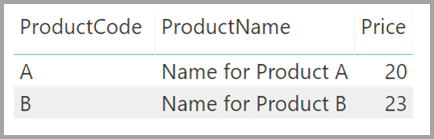
此外,假设“Sales”表只有四行,其中产品 C 占一行。由于出现了引用完整性错误,因此“Product”表中没有产品 C 对应的行 。
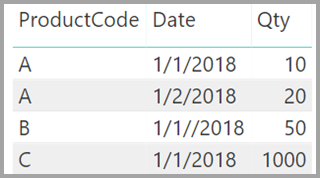
“ProductName”和“Price”(来自“Product”表),以及每个产品的总“Qty”(来自“ProductSales”表)如下图所示 :
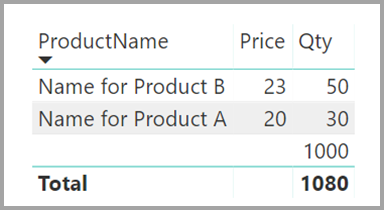
如上图所示,一个空白“ProductName”行与产品 C 的销售额相关联。此空行说明以下信息 :
“ProductSales”表中任何与“Product”表没有对应关系的行。 此处反应的是引用完整性问题,就像此示例中的产品 C 一样。
“ProductSales” 表中所有外键列是空的行。
因此,在这两种情况下,空白行表示 ProductName 和 Price 未知的销售。
有时,表是通过两个列联接起来,但这两个列都不是由唯一值构成的。 例如,考虑以下两个表:
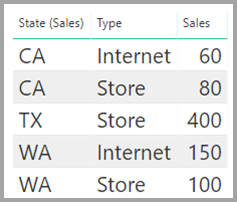
“Sales” 表按“State” 显示销售额数据,其中每一行都包含相应州采用的销售类型对应的销售额。 州包括“CA”、“WA”和“TX”。
“CityData”表显示城市数据,包括人口和州(例如“CA”、“WA”和“New York”) 。
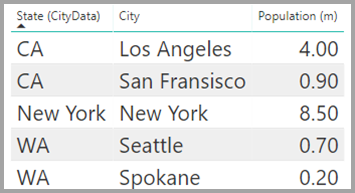
现在,这两个表中都有 State 列 。 要按州来报告总销售额和各州的总人口,这是合理的。 但是,存在一个问题:State 列在两个表中都不是唯一的 。
旧解决办法
在 2018 年 7 月之前发布的 Power BI Desktop 版本中,用户无法在这些表之间建立直接关系。 常见解决办法是:
创建仅包含唯一 State ID 的第三个表。 该表可为以下任意一项或所有项:
计算表(使用数据分析表达式 [DAX] 定义)。
基于 Power Query 编辑器中定义的查询的表,可显示从表之一中提取的唯一 ID。
组合的完整集。
然后,使用常见的多对一关系,将这两个原始表关联到此新表 。
可以使解决方法表保持可见。 或者,你可以隐藏解决方法表,这样它就不会出现在“字段”列表中 。 如果隐藏此表,多对一关系通常会设置为在两个方向上进行筛选,并且两个表中的“State”字段都可以使用 。 之后的交叉筛选会传播到另一个表。 这种方法如下图所示:
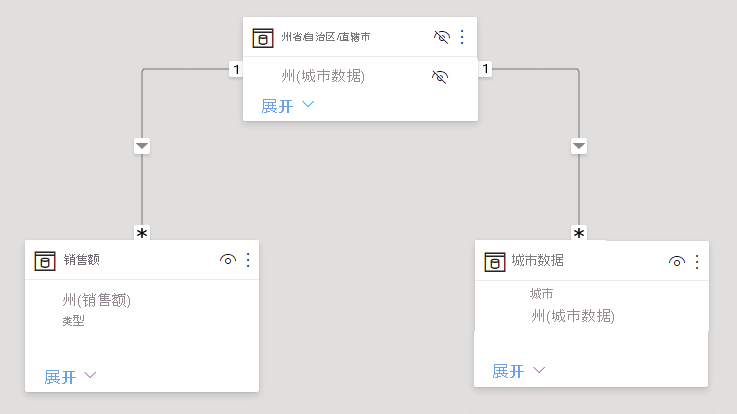
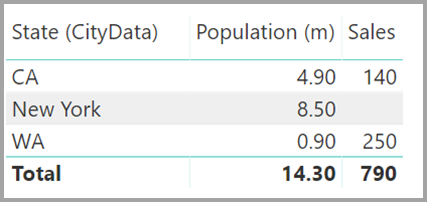
显示“State” (来自“CityData” 表)以及总“Population” 和总“Sales” 的视觉对象如下所示:
备注
因为此解决办法使用了“CityData”表中的州,所以只会列出这个表中的州(因此不包括“TX”) 。 此外,与多对一关系不同,虽然总计行包含所有“Sales”(包括 TX 的销售额),但详细信息中并没有一个空白行来对应不匹配行信息 。 同样,也没有空白行来对应 State 值为 Null 的 Sales。 。
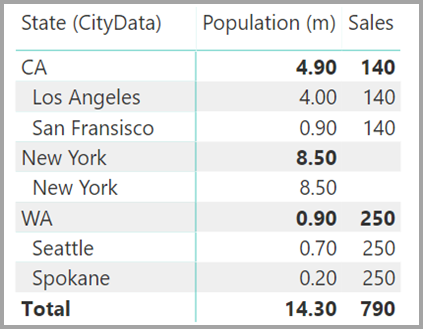
假设你还将“City”添加到该视觉对象。 尽管每个城市的人口是已知的,但针对“City”显示的“Sales”只会重复相应“State”的“Sales” 。 这种情况通常发生在列分组与某些聚合度量无关的情况下,如下所示:
假设将新的 Sales 表定义为此处所有 State 的组合,并使其在字段列表中可见 。 同一视觉对象将显示 State(在新表上)、Population 总数和 Sales 总额 :
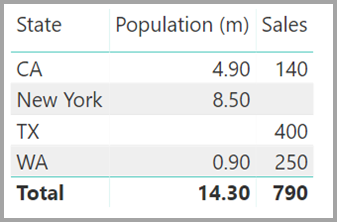
可以看到,表中 TX 的“Sales”数据已知,但“Population”数据未知,而表中 New York 的“Population”数据已知,但“Sales”数据未知。 这种解决办法并不是最佳的,也存在很多问题。 对于具有多对多基数的关系,可以解决所产生的问题,如下一部分所述。
有关实现此解决方法的详细信息,请参阅多对多关系指南。
使用具有多对多基数的关系,而非该解决办法
可以直接关联表(如之前所述的表),而不用必须采用类似的解决办法。 现在可以将关系基数设置为“多对多” 。 此设置表明,两个表都不包含唯一值。 对于此类关系,你仍然可以控制哪个表筛选另一个表。 或者,你可以应用双向筛选,使两个表相互进行筛选。
在 Power BI Desktop 中,当两个表中的关系列都不包含唯一值时,默认基数会被设置为“多对多” 。 在这种情况下,会出现一条警告消息,确认你确实想要设置关系,且此更改并不是数据问题的非预期效应。
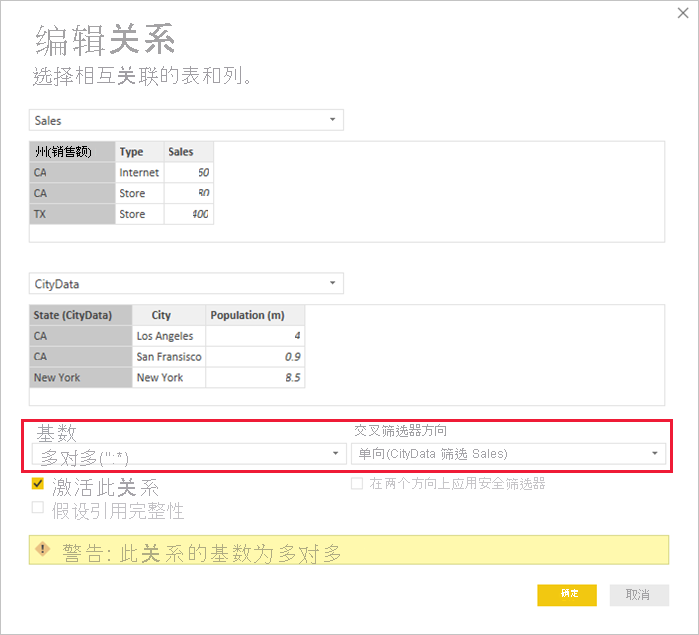
例如,如果直接在“CityData”和“Sales”之间建立关系(其中筛选器应从“CityData”流向“Sales”),Power BI Desktop 会显示“编辑关系”对话框:
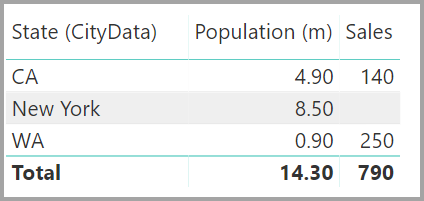
随即生成的“关系”视图 显示两个表之间的直接多对多关系。 表在“字段”列表中的外观以及表在视觉对象创建时的后续行为,都与应用解决办法时相似 。 在解决办法中,显示唯一“State”数据的附加表不可见。 如前文所述,显示 State、City Population 和 Sales 数据的视觉对象将显示为 :
具有多对多基数的关系与更典型的多对一关系的主要区别如下:
显示的值不包括说明另一个表中存在不匹配行的空白行, 此外,该值也不包括在另一个表的关系中使用的列为 Null 的行。
无法使用
RELATED()函数,因为可以关联多行。对一个表使用
ALL()函数不会删除通过多对多关系应用于其他相关表的筛选器。 在前面的示例中,此处定义的度量值不会删除对相关“CityData”表中列应用的筛选器:
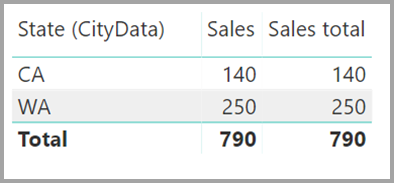
显示“State” 、“Sales” 和“Sales total” 数据的视觉对象将生成此图:
在注意到上述差异的同时,请确保使用 ALL(
) 的计算(如在总计中所占的百分比)返回的结果符合预期 。
注意事项和限制
此版本的具有多对多基数的关系和复合模型存在一些限制。
以下 Live Connect(多维)源不能用于复合模型:
SAP HANA
SAP Business Warehouse
SQL Server Analysis Services
Power BI 数据集
Azure Analysis Services
使用 DirectQuery 连接到这些多维数据源时,既无法同时连接到另一个 DirectQuery 源,也无法将它与导入数据相结合。
使用具有多对多基数的关系时,仍要遵守现有的 DirectQuery 使用限制。 现在每个表都要遵循许多限制,具体视表的存储模式而定。 例如,导入表中的计算列可以引用其他表,但 DirectQuery 表中的计算列仍只能引用同一表中的列。 如果模型中的任意表都是 DirectQuery,其他限制适用于整个模型。 例如,如果模型中任意表的存储模式为“DirectQuery”,QuickInsights 和问答功能在该模型上不可用。