


 400 998 0226
400 998 0226
 Tableau
Tableau







 Tableau
Tableau Minitab
Minitab




 Alteryx
Alteryx













 Neo4j
Neo4j










 Talend
Talend

















 IM
IM



 华为云
华为云 腾讯云
腾讯云 IT/安全
IT/安全









使用数据流制定解决方案
- 版本 :2023.1(当前版本)
使用数据流制定解决方案
Power BI 数据流是一种以企业为中心的数据准备解决方案,能够提供可供使用、重用和集成的数据生态系统。 本文介绍一些常见的应用场景。 指向文章和其他信息的链接可帮助你充分了解并使用数据流。
获取对数据流高级功能的访问权限
高级容量中的 Power BI 数据流提供了许多关键功能,可帮助数据流扩大规模和提高性能,例如:
高级计算,可加速 ETL 性能并提供 DirectQuery 功能。
增量刷新,使你能够加载从源更改的数据。
链接实体,可用于引用其他数据流。
计算实体,可用于生成包含更多业务逻辑的数据流的可组合构建基块。
出于这些原因,建议尽可能使用高级容量中的数据流。 Power BI Pro 许可证中使用的数据流可用于简单的小规模用例。
解决方案
可通过两种方式访问数据流的高级功能:
为给定工作区指定一个高级容量,并使用你自己的 Pro 许可证在此处编写数据流。
自带 Premium Per User (PPU) 许可证,这要求工作区的其他成员也拥有 PPU 许可证。
不能在 PPU 环境之外(例如在高级或其他 SKU 或许可证中)使用 PPU 数据流(或任何其他内容)。
对于高级容量,Power BI Desktop 中的数据流使用者不需要显式授权来使用并发布到 Power BI。 但若要发布到工作区或共享生成的数据集,至少需要 Pro 许可证。
对于 PPU,创建或使用 PPU 内容的每个人都必须具有 PPU 许可证。 此要求与 Power BI 的其余部分不同,因为你需要为所有用户显示授予 PPU,并且不能将免费、Pro 甚至高级容量与 PPU 内容混合使用,除非你将工作区迁移到高级容量。
选择模型通常取决于组织的规模和目标,但以下准则适用。
| 团队类型 | Premium Per Capacity | Premium Per User |
|---|---|---|
| >5,000 名用户 | ✔ | |
| <5,000 名用户 | ✔ |
对于小型团队而言,PPU 可以减少每容量的免费、Pro 和高级之间的差距。 如果你有更大的需求,那么对具有 Pro 许可证的用户使用高级容量是最佳方法。
创建具有安全性的用户数据流
假设你需要创建数据流以供使用,但有下列安全要求:
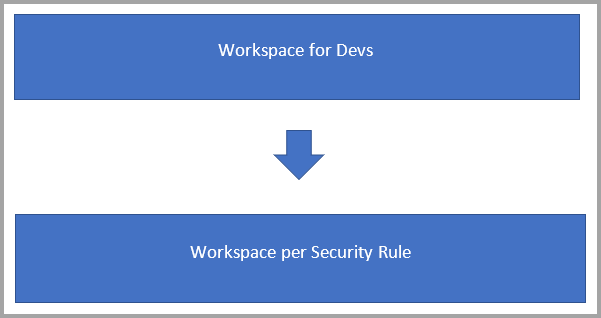
在此场景中,你可能有两种类型的工作区:
用于开发数据流和构建业务逻辑的后端工作区。
要向特定用户组公开一些数据流或表以供使用的用户工作区:
用户工作区包含指向后端工作区中数据流的链接表。
用户对使用者工作区具有查看者访问权限,但无法访问后端工作区。
当用户使用 Power BI Desktop 访问用户工作区中的数据流时,他们可以看到该数据流。 但由于数据流在导航器中显示为空,因此不会显示链接表。
了解链接表
链接表只是指向原始数据流表的指针,它们继承源的权限。 如果 Power BI 允许链接表使用目标权限,则任何用户都可以通过在指向源的目标中创建链接表来绕过源权限。
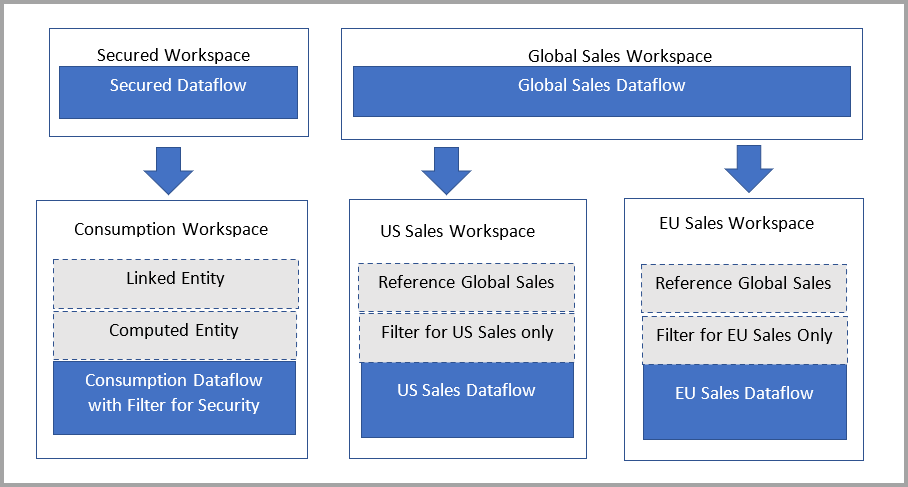
解决方案:使用计算表
如果你有权访问 Power BI Premium,可以在引用链接表的目标中创建一个计算表,其中包含链接表中的数据副本。 你可以通过投影删除列,通过筛选器删除行。 具有目标工作区权限的用户可以通过此表访问数据。
有特权的个人的世系还将显示引用的工作区,并允许用户链接回去,以完全了解父数据流。 对于没有特权的用户,仍保留隐私。 只显示工作区的名称。
以下图表展示了这种设置。 左侧是体系结构模式。 右侧是显示按区域拆分和保护的销售数据示例。
缩短数据流的刷新时间
假设数据流较大,但你想要从该数据流生成数据集,并减少刷新它所需的时间。 通常,完成从数据源 > 数据流 > 数据集的刷新需要很长时间。 冗长的刷新是难以管理或维护的。
解决方案:使用为引用表显式配置了“启用加载”的表,不要禁用加载
Power BI 支持简单的数据流业务流程,如了解和优化数据流刷新中定义的那样。 利用业务流程需要将任何下游数据流显式配置为“启用加载”。
通常只有在加载更多查询的开销取消正在开发的实体的好处时,禁用加载才适用。
虽然禁用加载意味着 Power BI 不会评估给定查询,但当将其作为成分(即在其他数据流中引用)使用时,也意味着 Power BI 不会将其视为现有表,我们可以在其中提供指针并执行折叠和查询优化。 在此意义上,执行联接或合并等转换只是两个数据源查询的联接或合并。 此类操作会对性能产生负面影响,因为 Power BI 必须再次完全重载已计算的逻辑,然后才能应用任何其他逻辑。
若要简化数据流的查询处理并确保进行任何引擎优化,请启用加载并确保 Power BI Premium 数据流中的计算引擎设置为默认设置(即“优化”)。
启用加载还可以保留完整的世系视图,因为 Power BI 会将未启用加载的数据流视为新项。 如果世系对你很重要,请不要对连接到其他数据流的实体或数据流禁用加载。
缩短数据集的刷新时间
假设你的数据流很大,但你需要基于该数据流生成数据集并减少业务流程。 完成从数据源 > 数据流 > 数据集的刷新需要很长时间,这就增加了延迟。
解决方案:使用 DirectQuery 数据流
每当工作区的增强的计算引擎 (ECE) 设置被显式配置为“启用”时,都可以使用 DirectQuery。 当数据无需直接加载到 Power BI 模型时,此设置很有用。 如果你是第一次将 ECE 配置为“启用”,则允许 DirectQuery 的更改将在下次刷新期间发生。 当你启用它时,需要刷新它,使它立即发生更改。 由于 Power BI 将数据写入存储和托管 SQL 引擎,因此初始数据流负载上的刷新可能会变慢。
总而言之,将 DirectQuery 用于数据流,可以让 Power BI 和数据流过程得到以下增强:
避免单独刷新计划:DirectQuery 直接连接到数据流,无需创建导入的数据集。 因此,将 DirectQuery 与数据流一起使用意味着不再需要数据流和数据集的单独刷新计划,就能确保数据已同步。
筛选数据:DirectQuery 对于处理数据流中经过筛选的数据视图非常有用。 如果你要筛选数据并处理数据流中较小的数据子集,可以使用 DirectQuery(和 ECE)来筛选数据流数据,并处理筛选出的子集。
通常,与导入模式相比,使用 DirectQuery 将使数据集中的数据保持最新状态,但报表性能会下降。 只有在以下情况下,才考虑使用此方法:
用例需要来自数据流的低延迟数据。
数据流有大量数据。
导入可能会花费太长时间。
你愿意用缓存性能来换取最新的数据。
解决方案:使用数据流连接器为导入启用查询折叠和增量刷新
统一的数据流连接器可以显著缩短对计算实体执行的步骤的评估时间,例如执行联接、分离、筛选和分组操作。 有两个特定优势:
在 Power BI Desktop 中连接到数据流连接器的下游用户可以在创作场景中利用更好的性能,因为新连接器支持查询折叠。
数据集刷新操作还可以折叠到增强的计算引擎,这意味着,甚至数据集中的增量刷新也可以折叠到数据流。 此功能可以提高刷新性能,并可能降低刷新周期之间的延迟。
若要为任何高级数据流启用此功能,请确保计算引擎显式设置为“启用”。 然后,在 Power BI Desktop 中使用数据流连接器。 必须使用 2021 年 8 月版 Power BI Desktop 或更高版本才能利用此功能。
若要将此功能用于现有解决方案,必须拥有 Premium 或 Premium Per User 订阅。 可能还需要对数据流进行一些更改,如使用增强的计算引擎中所述。 必须通过将“源”部分中的 PowerBI.Dataflows 替换为 PowerPlatform.Dataflows,更新任何现有 Power Query 查询以使用新连接器。
Power Query 中的复杂数据流创作
假设你有一个包含数百万行数据的数据流,但你想要使用它构建复杂的业务逻辑和实现转换。 你需要遵循处理大型数据流的最佳做法。 还需要数据流预览功能才能快速执行。 但是,你有数十列和数百万行的数据。
解决方案:使用架构视图
可以使用架构视图,该视图旨在通过将查询的列信息置于前端和中心,来优化在处理架构级操作时的流程。 架构视图提供上下文交互来调整数据结构。 架构视图还提供较低延迟操作,因为它只需要计算列元数据,不需要计算完整的数据结果。
处理更大的数据源
假设你在源系统上运行查询,但不希望提供对系统的直接访问或使访问大众化。 你计划将这些数据置于数据流中。
解决方案 1:对查询使用视图或优化查询
使用优化的数据源和查询是最佳选择。 通常,数据源最适合用于针对它的查询。 Power Query 的高级查询折叠功能可以委托这些工作负载。 Power BI 还在 Power Query Online 中提供步骤折叠指示器。 有关更多的指示器类型,请参阅步骤折叠指示器文档。
解决方案 2:使用本机查询
你还可以使用 Value.NativeQuery() M 函数。 在第三个参数中设置 EnableFolding=true。 此网站上记录了 Postgres 连接器的本机查询。 它还适用于 SQL Server 连接器。
解决方案 3:将数据流分解为引入数据流和使用数据流,以利用 ECE 和链接实体
通过将数据流分解为单独的引入和使用数据流,可以利用 ECE 和链接实体。 有关此模式以及其他模式的详细信息,请参阅最佳做法文档。
尽可能确保客户使用数据流
假设你有许多数据流提供了共同用途,例如符合要求的维度(如客户、数据表、产品和地理位置)。 Power BI 的功能区中提供了这些数据流。 理想情况下,你会希望客户主要使用你创建的数据流。
解决方案:使用认可来认证和提升数据流
若要详细了解认可的工作方式,请参阅认可 - 提升和认证 Power BI 内容。
Power BI 数据流中的可编程性和自动化
假设你有业务需求,需要在 Power BI 之外自动完成导入、导出或刷新,以及更多业务流程和操作。 有几个选项可用于实现此目的,如下表所述。
| 类型 | 机制 |
|---|---|
| 使用 PowerAutomate 模板。 | 无代码 |
| 使用 PowerShell 中的自动化脚本。 | 自动化脚本 |
| 使用 API 构建你自己的业务逻辑。 | REST API |
有关刷新的详细信息,请参阅了解和优化数据流刷新。
务必要保护数据资产下游
可以使用敏感度标签来应用数据分类,以及在连接到数据流的下游项上配置的任何规则。 若要详细了解敏感度标签,请参阅 Power BI 中的敏感度标签。 若要了解继承关系,请参阅 Power BI 中的敏感度标签下游继承。
多地理位置支持
如今,许多客户都需要满足数据主权和驻留要求。 可以完成对数据流工作区的手动配置,使之成为多地理位置的工作区。
当数据流使用自带存储帐户功能时,它们支持多地理位置。 将数据流存储配置为使用 Azure Data Lake Gen 2 中介绍了此功能。 在附加此功能之前,工作区必须为空。 对于此特定配置,可以将数据流数据存储在你选择的特定地理区域中。
务必要保护虚拟网络背后的数据资产
如今,许多客户都需要保护专用终结点后面的数据资产。 为此,请使用虚拟网络和网关来保持符合性。 下表描述了当前的虚拟网络支持信息,并说明了如何使用数据流来保持符合性并保护数据资产。
| 方案 | 状态 |
|---|---|
| 通过本地网关读取虚拟网络数据源。 | 通过本地网关支持 |
| 使用本地网关将数据写入虚拟网络背后的敏感度标签帐户。 | 尚不支持 |